![]()
![]()
Artsdata Data Model v0.2
A simple data model for Performing Arts Events and related Places, People and Organizations.
The Artsdata data model (ontology) is a sub-set of Schema.org along with a few controlled vocabularies specific to Artsdata. The data mode is formally represented using the language SHACL here.
The classes and properties used in Artsdata resemble Google Event Structured Data. The main difference is that Artsdata creates links between entities within Artsdata and interlinks URIs outside of Artsdata including links to Wikidata and other LOD (Linked Open Data) sources. Artsdata also generates unique global identifiers (IRIs also called URIs) for classes such as Events, Persons, Places, and Organizations.
Here are the main Classes used in Artsdata.
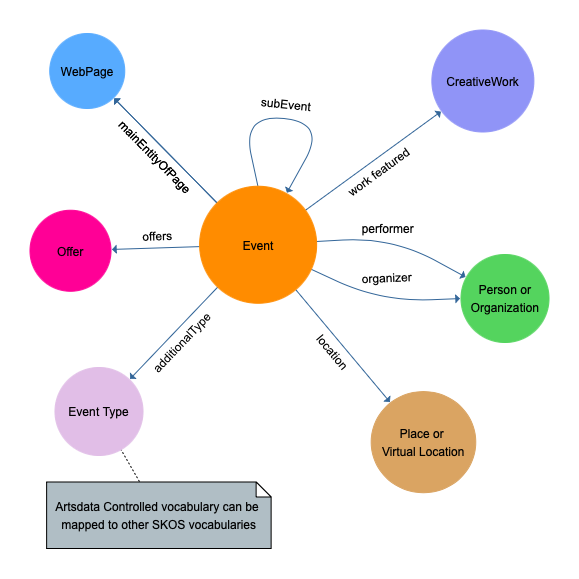
Classes
- EventAttendanceModeEnumeration
- EventStatusType
- Event
- Offer
- Organization
- Person
- Place
- PostalAddress
- VirtualLocation
- WebPage
Controlled vocabularies
Persistent Identifiers
In addition to Artsdata Identifiers, the Artsdata Knowledge Graph relies on other unique persistent identifiers, like Wikidata and ISNI, to recognize and reconcile entities of type Organization, Person and Place.
Guidelines regarding persistent identifiers for data providers
Structured Data Templates
SHACL Validation Reports
SHACL shapes are used to validate data before importing.
Ontologies & Inferencing
Artsdata.ca uses a basic set of RDFS and OWL entailments (or ruleset) to enable simple inferencing, called OWL-Horst (optimized).
The main ontology used in Artsdata.ca is Schema.org. Artsdata.ca imports the core Schema.org schema and the pending Schema.org schema (to include schema:EventSeries which is a pending class).
Artsdata.ca has a large number of class and property mappings between Schema.org, Wikidata.org, DBpedia.org, FOAF and DOLCE+DnS Ultralite (Ontology Design Patterns) using owl:equivalentClass and owl:equivalentProperty. The mappings come prebuilt from external ontologies.
Current work into the next version of the Artsdata.ca ontology is being influenced by the work at CAPACOA’s Linked Digital Future initiative and involves aligning the data model with data models used in cultural heritage including, but not limited to, CIDOC-CRM, FRBRoo, PROV and RDA. The data models will be futher specificed by a domain-specifc vocabulary to be released in the upcoming versions.
Exceptions handling schema.org in Artsdata
Artsdata converts all schema.org https URIs to http URIs, and also makes the following transformations:
- schema:eventStatus and schema:eventAttendanceMode are converted to URIs in Artsdata, whereas the schema.org @context defines them as Literals.
- datatype schema:Date and schema:DateTime are converted to xsd:date or xsd:dateTime to enable SPARQL to handle time.
- schema:LocalBusiness and it’s subClasses are replaced with schema:Place to ensure that schema:Organization and schema:Place are disjoint (meaning a Place cannot be an Organization and vice versa).
Ontologies loaded into Artsdata
Provenance
Data is great, but it is not the ultimate truth, and without traceability it can lose our trust. For example, what if two web pages have different dates for the same performing arts event. Which source is more trust worthy? How can we follow the data back to the source to decide for ourselves?
Artsdata.ca tracks data provenance in 2 different ways:
- Data feed metadata attached to named graphs. Each data feed source in Artsdata.ca is stored in a separate named graph. The graph’s URI is used as the subject of the provenance metadata. This technique to track provenance is generally called the Named Graphs approach. Each named graph URI is a prov:Entity and is linked to provenance metadata including the date when the data feed was loaded, the software used to collect it and the email of the contributing organization. Each time a data feed is imported, whether by crawling a web site, using an JSON API or loading a spreadsheet, the graph’s provenance metadata is updated.
- Core data annotations with RDF-star. Core data in Artsdata for all minted entities have provenance tracked using RDF-star and the Provenance Ontology (using prov:wasDerivedFrom and for:wasGeneratedBy).
Data Flow Architecture
In principle, anyone can add data to Artsdata.ca as long as certain data requirements are met. Here is a diagram about how data flows in and out of Artsdata.ca.
Caching LOD
Artsdata.ca loads LOD from Wikidata and DBpedia in order to cache it for performance reasons. The triples are obtained using content negotiation (instead of data dumps) and are cached unmodified in their respective named graphs.
Note: there is one notable exception, the Wikidata property P31 (instance of) is transformed to rdf:type. This same result could have been accomplished using owl:equivalentProperty but it was not selected for performance reasons.
Naming Conventions
Conventions on how to name things when in doubt.
Support or Contact
Contact support and we’ll help you sort it out.